Khadas VIM3 – a single board computer like a Raspberry Pi or Jetson Nano – but with more powerful processors.
Uses Amlogic A311D SoC and includes a neural processing unit for accelerating machine learning models and AI computations
Ideal for embedded computer vision or deep learning projects!

Installing Linux
The VIM3 comes with an Android OS pre-loaded which we need to replace for Linux. Khadas have good documentation for how to do this.
First setup a workspace for Khadas on the host machine (Ubuntu 20).
cd ~
mkdir Khadas
cd Khadas
Choosing OS Image
The first step is to choose an OS. Some decisions to make:
- What kernel to use: can choose between the older more stable 4.9 kernel, or the latest (less stable?) mainline kernel.
- Where to store the OS on the board: can install the image on an SD card and insert it into the slot, or, can flash the OS directly to the onboard storage. The onboard eMMC is faster and more stable than SD cards.
- Whether to have command line only or install the desktop GUI: we wanted the full desktop as we will want to be able to use the GUI when out and about.
This case: use the VIM3_Ubuntu-gnome-focal_Linux-4.9_arm64_EMMC_V1.0.9-211217 image as we want the desktop Ubuntu installed in eMMC with 4.9 kernel.
Flashing OS Image
Make a separate directory for OS images and download the image
mkdir images curl https://dl.khadas.com/Firmware/VIM3/Ubuntu/EMMC/VIM3_Ubuntu-gnome-focal_Linux-4.9_arm64_EMMC_V1.0.9-211217.img.xz --output images/VIM3_Ubuntu-gnome-focal_Linux-4.9_arm64_EMMC_V1.0.9-211217.img.xz
extract the the file using unxz.
unxz images/VIM3_Ubuntu-gnome-focal_Linux-4.9_arm64_EMMC_V1.0.9-211217.img.xz
To load the OS image onto the board we need the Khadas burning tool. Install the dependencies for disk tools first.
sudo apt-get install libusb-dev git parted
Then download the Khadas utils repository using git
git clone https://github.com/khadas/utils cd utils
Then to setup the imaging tool:
sudo ./INSTALL
To flash the image and load the new OS, the board needs to be booted into upgrade mode.
- Connect the board to the host PC using the USB C connection.
- After its connected, wait for the board to boot up and its red LED to light up.
- Find the power button and reset button. Power is one of the 3 buttons, closest to the GPIO pins. Reset is one of the 3 buttons, closest to the USB port.
- While holding the power button, click the reset button, and continue to hold the power button for 3 seconds afterwards.
- The LED should blink and end up white.
- To confirm the board is in upgrade mode, type
lsusb | grep Amlogic
Should see something like:
BUS 002 Device 036: ID 1b8e:c003 Amlogic, Inc.
Otherwise, do the upgrade mode sequence again. When you can see the Amlogic listed like above, run the burn tool.
burn-tool -v aml -b VIM3 -i ../images/VIM3_Ubuntu-gnome-focal_Linux-4.9_arm64_EMMC_V1.0.9-211217.img
Should see output like:
dan@antec:~/Khadas/utils$ burn-tool -v aml -b VIM3 -i ../images/VIM3_Ubuntu-gnome-focal_Linux-4.9_arm64_EMMC_V1.0.9-211217.img Try to burn Amlogic image... Burning image '../images/VIM3_Ubuntu-gnome-focal_Linux-4.9_arm64_EMMC_V1.0.9-211217.img' for 'VIM3/VIM3L' to eMMC... Rebooting the board ........[OK] Unpacking image [OK] Initializing ddr ........[OK] Running u-boot ........[OK] Create partitions [OK] Writing device tree [OK] Writing bootloader [OK] Wiping data partition [OK] Wiping cache partition [OK] Writing logo partition [OK] Writing rootfs partition [OK] Resetting board [OK] Time elapsed: 8 minute(s). Done! Sat 19 Feb 17:45:01 GMT 2022
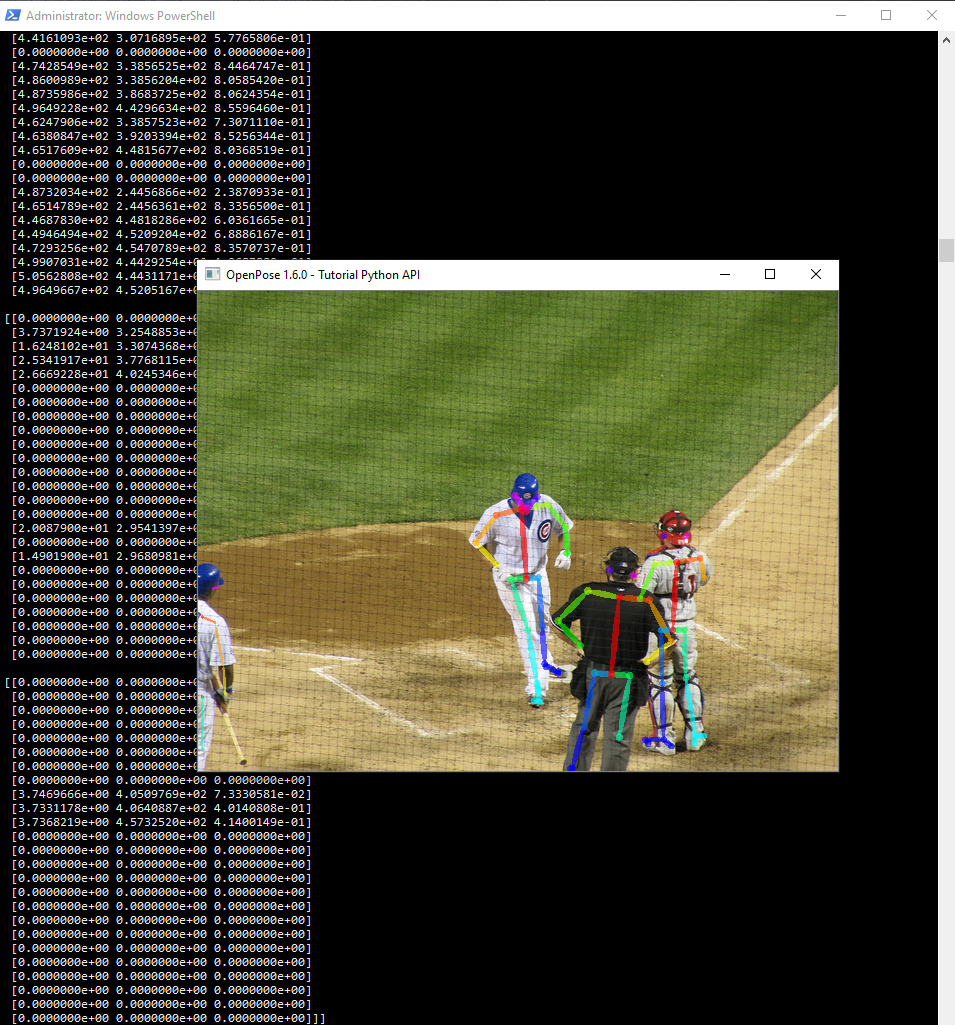
Running object detection on the NPU
Follow the Tengine docs